AI agents are easy to demo — but surprisingly hard to make useful in real productionenvironments.
Over the past year, as we experimented with internal GPTs, fine-tuning, RAG, and open-source models, one thing became very clear: agents only work well when they are deeplyconnected to the systems they reason about. That means real access to infrastructure,telemetry, code, and workflows — across clouds.
This post focuses on how we’re building AI agents using DGX Spark, and how Alkira CXPs provide the seamless, secure multi-cloud connectivity that makes these agents effective.
From Models to Agents
Early on, most of our experimentation was model-centric — trying different sizes, fine-tuning approaches, and prompt strategies. That was useful, but once we started thinkingabout agents instead of chat interfaces, a different set of challenges showed up.
Agents need access to things like:
- Kubernetes clusters
- Metrics, alerts, and logs
- Source control and internal tools
- Collaboration systems
Without that access, agents don’t fail loudly — they just make shallow or incompletedecisions. We found that once agents start touching real systems, architecture andintegration matter more than clever prompting.
That wasn’t obvious at the beginning — it became clear only after a few failed attempts.
Security and Cost Show Up Early
As soon as agents started interacting with real infrastructure, two concerns surfacedalmost immediately: security and cost.
Security: Learning to Be Careful First
Agents need credentials to do useful work — API tokens, roles, certificates. Our initialinstinct was to move quickly, but it became clear that uncontrolled access would be a long-term problem.
Instead of letting agents talk directly to systems, we ended up writing MCP servers for ourinternal systems. These act as controlled gateways where we explicitly define what anagent can see or do.
We started very conservatively:
- Read-only access
- No ability to change infrastructure
- Everything observable and auditable
Only after running agents this way for a while — and building confidence — did we beginallowing limited corrective actions, still tightly scoped and always routed through MCP. Thisincremental approach slowed us down early, but paid off later.
Cost: Agents Don’t Sleep
Cost showed up in a different way.
Many of these agents aren’t invoked occasionally — they’re designed to run continuously,watching systems, correlating signals, and doing background work. At that point, inferencecosts compound quickly, especially if every decision involves an external API call.
We didn’t want to discover six months later that something “useful” was quietly burningbudget.
That pushed us to:
- Separate continuous observation from deeper reasoning
- Use smaller, task-specific models where possible
- Be deliberate about when agents actually invoke inference
- Track cost alongside latency and accuracy
None of this was theoretical — it emerged naturally as agents stayed running longer.
Why DGX Spark Entered the Picture
As the number of agents grew, we wanted more control over inference behavior and cost.That’s where
DGX Spark became useful for us.
Running models locally gave us:
- Predictable performance
- Building Practical AI Agents with DGX Spark and Alkira CXPs 2
- Control over model choice and size
- Fewer external dependencies
- A clearer picture of resource usage
It also made iteration easier. We could experiment with different agent behaviors withoutworrying about API limits or variable latency. This didn’t replace cloud-hosted models entirely, but it gave us another tool that fit certain workloads better.
As part of this work, we evaluated readily available models such as Gemini Flash, Haiku,and larger Qwen3 variants. In practice, we found that Qwen3-30B running locally on DGXSpark performed comparably when paired with clear, controlled prompts and well-structured inputs. Much of this consistency came from the systems around the models —code that generated normalized, structured data and presented signals in a form that waseasy for models to consume and reason over — reinforcing that strong pipelines oftenmattered more than raw model size.
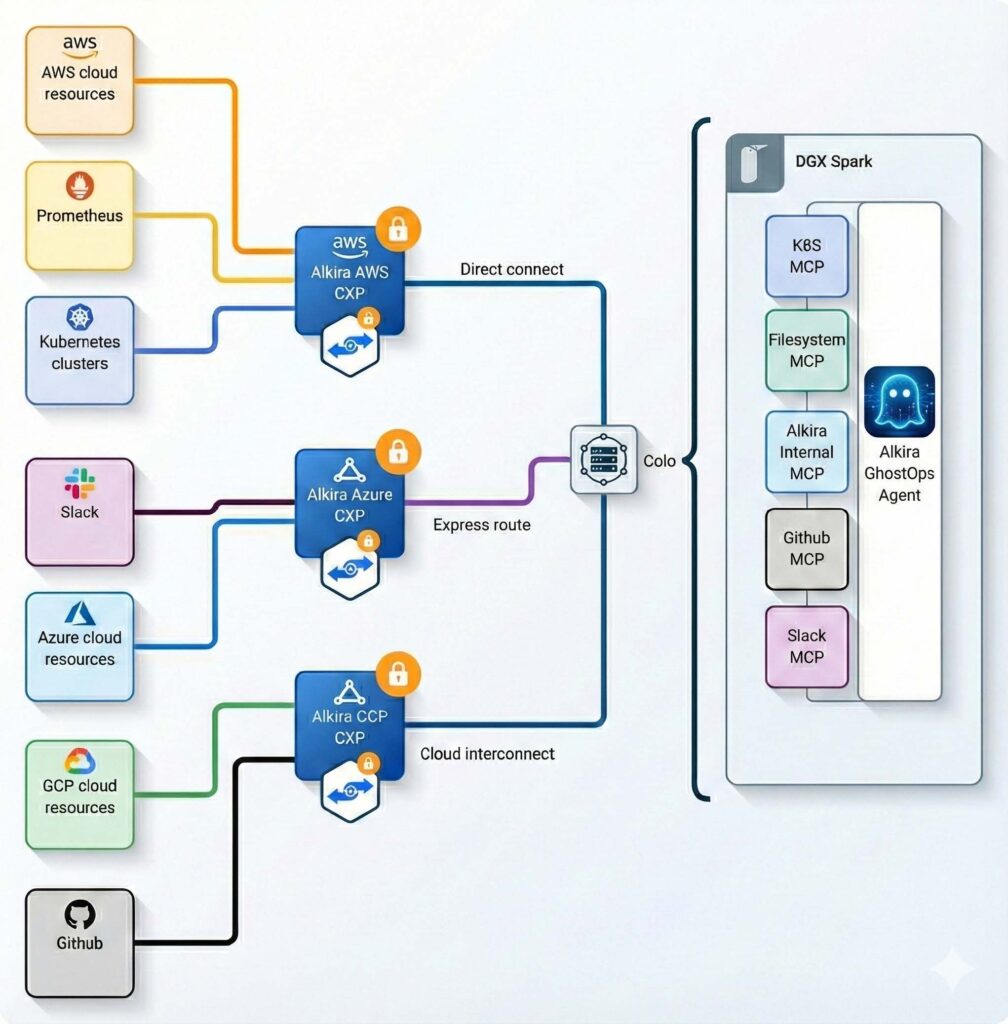
Connectivity Turned Out to Matter a Lot
One thing we underestimated early was how much connectivity influences agenteffectiveness.
Our systems span:
- Multiple public clouds
- Kubernetes clusters
- Observability stacks
- Source control and internal services
Alkira CXPs helped simplify this by giving us a consistent, secure network layer acrossenvironments. That didn’t magically make agents smarter — but it removed a lot of friction.Agents could access systems reliably without needing cloud-specific logic baked into theirbehavior.
Over time, this made agent behavior more predictable and easier to reason about.
A Practical Agent Example
One of the agents we built focuses on infrastructure operations.
It can:
- Observe alerts
- Pull related metrics
- Inspect Kubernetes state
- Look at recent code changes
- Summarize findings for humans
What made this work wasn’t any single model choice. It was the combination of:
- Controlled access through MCP
- Stable inference on DGX Spark
- Reliable connectivity via CXPs
Each piece on its own helped a little. Together, they made the agent usable day-to-day.
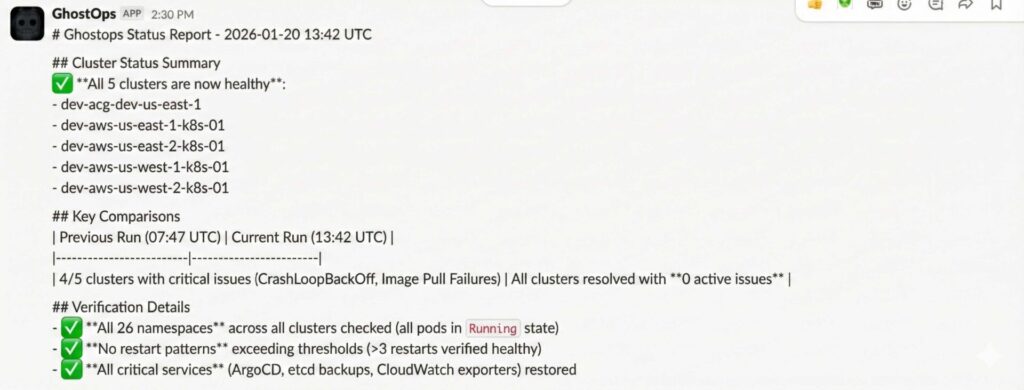
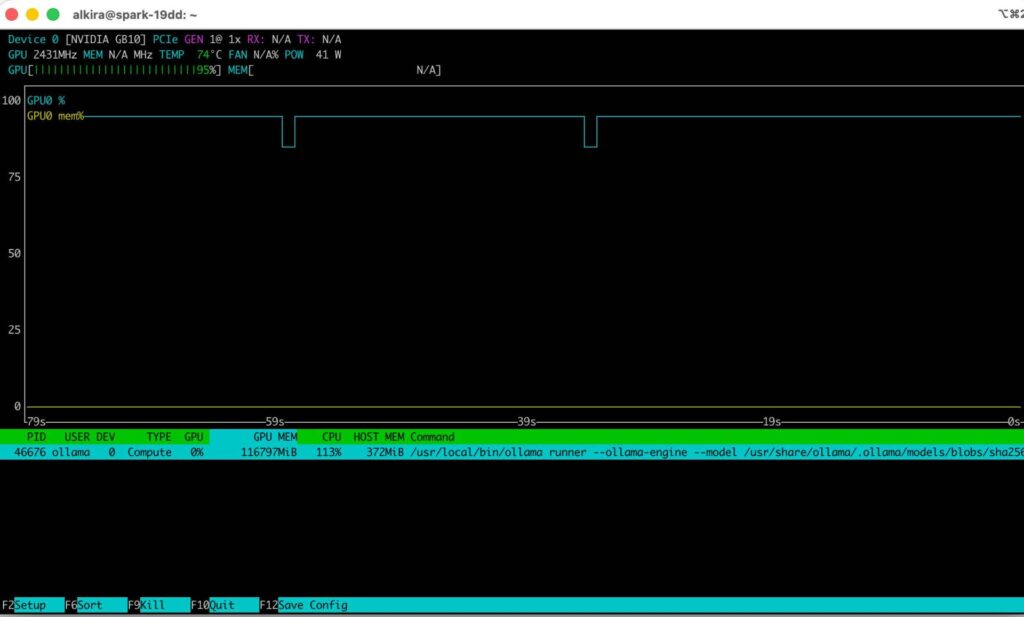
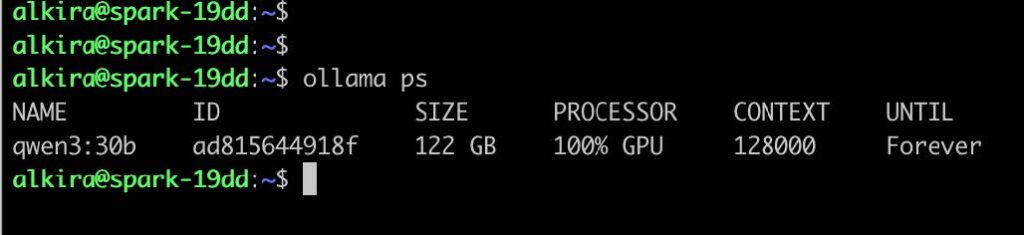
Qwen3-30B running locally on DGX Spark via Ollama — real inference, real GPUs, no APIcalls.
Things We Learned Along the Way
A few observations that emerged through experimentation:
- Agents behave more like distributed systems than chatbots
- Most failures come from integration gaps, not model quality
- Read-only agents build trust faster than autonomous ones
- Small models are often enough for narrow tasks
- Cost problems appear gradually, not immediately
- Network reliability mattered more than we initially expected. Agents depend onconsistent, low-latency connectivity to function correctly. When connectivity isunreliable, agents don’t always fail loudly — they often just hang, stall, or producepartial results. Making the network predictable turned out to be just as important asmodel choice.
None of these were obvious at the start.
What We’re Still Exploring
We’re still exploring how to make these agents more reliable, cost-effective, and trustworthy in real environments. What we’ve learned so far is that effective agents are built on strong systems foundations — controlled access, predictable connectivity, and stable inference — more than on clever prompts. That’s where practical AI starts to matter: not in demos, but in dependable day-to-day operations.
FAQs
Further Reading
Technical “Building A New Operating Model” Blog Series
Technical Blog Part 1: “Building A New Operating Model: The Architectural Evolution of an Enterprise RAG System”

Santosh Kumar Dornal